Exploring Speculative Decoding: From Concept to Implementation
In this post, we explore speculative decoding through a concrete vLLM-focused implementation, covering draft models, EAGLE, MTP, and the tradeoffs involved.
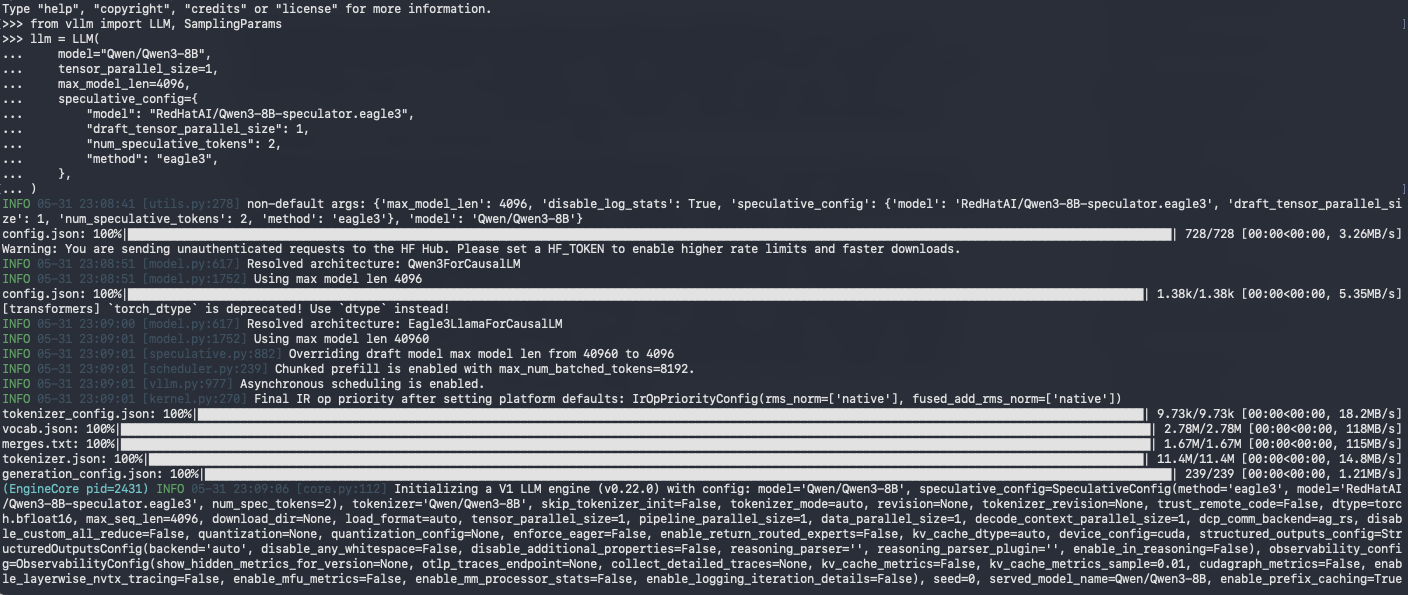
Intro
In this post, I’ll discuss speculative decoding, a technique used to optimize LLM inference. It’s one those things that when you first learn about it, it somehow just clicks in an “oh yeah! that makes sense” way.
But first, I want to motivate why LLM inference optimzation matters.
LLMs generate responses to user queries. We train large models once, often at 8- or 9-figure costs, but serving them is what happens millions of times. Running a model requires some serious hardware, and saying GPUs are expensive and are in limited supply is almost an understatement. A small efficiency gain means very large savings over time.
Refresher on LLM Inference Basics
Modern GPUs are impressive beasts. But they have their quirks. A GPU can run hundreds of trillions of operations per second, yet it can only move a few trillion bytes from GPU memory to the compute units.
LLM inference is autoregressive. If we have some input tokens [t_1 .. t_n], the model gives us a logits vector of size vocab_size for each token in the sequence. We use the logits of the last tokent_n to sample the the next token t_{n+1}.
That means unless we run hundreds of operations per byte — which we don’t in LLMs — we’re essentially memory-bandwidth bound.
When we batch, we perform more ops per set of weights (X @ W): the larger the batch, the more we reuse the weights (W) we brought from memory, and the better we utilize the GPU.
From KV Cache to Speculative Decoding
Each token goes through multiple layers, and each layer has a few standard blocks: normalization, MLP, and most notably the transformer’s attention block. In every block before attention, a token does not care about other tokens. In attention, token t_i needs to know about tokens t_0 .. t_{i-1}. Specifically, it needs access to the keys and values for those tokens at that particular layer.
One key optimization that LLM inference engines bring to the table is that, instead of recalculating those K and V tensors for every new token, we store them and only run the calculation for the new tokens. That is the famous KV cache. As new tokens go through the model, their key and value vectors are added to the cache.
The sampled token t_{n+1} is added to the input, and its logits are used to sample t_{n+2} and so on. During the first model run, we calculate n logits vectors in the output even though we only need the last one for generation. And the difference between calculating 1 or a few candidate tokens in the same forward pass is often much smaller than running several decode steps one after the other.
For each run or forward pass that produces a new token, we need to load all the models weights and we need to reload them for the next one and so on. And since the memory bandwidth is the limiting factor, we’re waiting for weights to be loaded most of the time.
That is where speculative decoding comes in. If we can guess a few likely tokens ahead of time and feed them to the model, we can verify them in one pass. If they are correct, we get those tokens almost for free. f Regular:
[t_1 .. t_n] => t_{n+1}
Spec dec:
[t_1 .. t_n] => t_{n+1}, t_{n+2}, t_{n+3}, ...
Of course, this only works if the guessed tokens, which we call draft tokens, are usually correct and the guessing process is much cheaper than a full forward pass on the target model. If not, we might as well just use the large original model, which we refer to as the target.
There are many techniques to generate these draft tokens: n-gram, EAGLE, MTP, and others.
But the idea is the same. One forward pass is normally used to sample one token. If we can run a cheaper draft process and predict a few extra tokens, we can reduce the number of expensive target-model steps. If we do things right, we can also preserve the target model’s distribution exactly, as if there were no draft model at all.
Pseudo code
1
2
3
4
5
6
7
8
9
10
def propose(tokens, num_speculative_tokens):
draft_tokens = []
for _ in range(num_speculative_tokens):
logits = generate_draft_token(tokens) # this must be very fast compared to the target model
token = sample(logits)
draft_tokens.append(token)
tokens.append(token)
return tokens, draft_tokens
Once we have the draft tokens, we verify them:
1
2
3
4
5
6
7
8
9
10
11
12
def sample_verify(tokens, num_drafts):
logits = target_model(tokens) # run target model forward, this is the true distribution
for i, logit in enumerate(logits[-num_drafts:]):
target_token = sample(logit)
draft_token = tokens[-num_drafts + i]
if target_token == draft_token:
accept(draft_token)
else:
reject(draft_token)
break
Guaranteeing The Original Distribution
The important part is that speculative decoding doesn’t sacrifice correctness for speed. The final output follows the same distribution as the target model.
This is mathematically provable if we follow this algorithm:
1
2
3
4
5
6
7
8
# this step should be way faster than regular decode
1. Sample tokens using the draft model via probability distribution q(x)
# verify multiple tokens cheaply in one pass
2. Target model computes true distribution p(x)
3. Accept the sampled token with probability `min(1, p(x)/q(x))`. Two cases:
a. If p(x) >= q(x), we accept with probability 1. the target likes the token at least as much as the draft, so we keep it.
b. If p(x) < q(x), we accept with probability p(x)/q(x), which is less than 1.
4. If rejected, sample a correction token from max(0, p(x)-q(x))
Step 4 is key: it’s where we account for the discrepancy between the draft and target. By resampling from p-q, we cover the tokens the draft was overlooking.
Step 3b is also important. If the draft thinks token 2 has probability 0.4 but the target thinks it’s 0.2, then p/q = 0.2/0.4 = 0.5, so we accept it half the time. This makes sense: the draft is overconfident, and we correct for that via the ratio p/q.
If p > q, the target likes the token more than the draft does, so we just accept it.
Speculators
There are many ways to get these draft tokens. The criteria we are optimizing for are being as close as possible to the target model and being faster.
Smaller Draft Model
The most intuitive one is probably using a smaller model. Imagine you have a 470B model and you rely on a 7B model from the same family.
For complex tokens, the small model will not perform well, but for repetitive and easy stuff, it should be decent. For example:
Q: How can we solve special relativity? A: To solve special ...
The small model should easily guess that we will repeat part of the question and provide appropriate draft tokens. The rest of the answer is harder, but if we get the easy parts right, we still come out ahead.
We can come up with different techniques to generate draft tokens. It is just a function that takes the existing sequence and tries to predict K draft tokens. In vLLM, this is implemented as a pluggable speculator.
The snippets below are trimmed from vLLM and keep only the skeleton and the key data flow.
The shared proposer base looks like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class SpecDecodeBaseProposer:
def __init__(self, vllm_config, device, pass_hidden_states_to_model, runner=None):
@torch.inference_mode()
def propose(
self,
target_token_ids,
target_positions,
target_hidden_states,
next_token_ids,
token_indices_to_sample,
common_attn_metadata,
sampling_metadata,
mm_embed_inputs=None,
num_rejected_tokens_gpu=None,
slot_mappings=None,
):
# Take in current token and extra data that might be used (depending on the proposer)
# then generate draft tokens and their draft logits/probs
...
N-gram
Things tend to repeat themselves. What goes around comes around. This is a general principle in computing that underlies caching: if we see some data, we are likely to use it again. That is locality. Following this principle, we can look at the last N tokens in our sequence and search for a previous occurrence. Our draft tokens are then the K tokens that came after that previous occurrence.
From the example above, the suffix of the sequence is “solve special”, its previous occurrence is a few words earlier, and what comes after it is “relativity?”. We guess that as the likely draft tokens, and we end up being right.
N-gram is a very simple and cheap technique to run. We can even run it on the CPU. Its simplicity also means that it is often wrong in practice, but it can be quite useful for text with repetitive patterns, and code is the perfect example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
class NgramProposer:
def __init__(self, vllm_config):
# Draft length and match window come from speculative config.
self.min_n = vllm_config.speculative_config.prompt_lookup_min
self.max_n = vllm_config.speculative_config.prompt_lookup_max
self.k = vllm_config.speculative_config.num_speculative_tokens
self.max_model_len = vllm_config.model_config.max_model_len
def propose(self, sampled_token_ids, num_tokens_no_spec, token_ids_cpu, slot_mappings=None):
# Only speculate for requests that actually sampled a token.
valid_requests = [i for i, sampled_ids in enumerate(sampled_token_ids)
if sampled_ids and num_tokens_no_spec[i] < self.max_model_len]
return self.batch_propose(len(sampled_token_ids), valid_requests, num_tokens_no_spec, token_ids_cpu)
def batch_propose(...):
for i in prange(len(valid_ngram_requests)):
idx = valid_ngram_requests[i]
num_tokens = num_tokens_no_spec[idx]
context_token_ids = token_ids_cpu[idx, :num_tokens]
drafter_output = _find_longest_matched_ngram_and_propose_tokens(
origin_tokens=context_token_ids,
min_ngram=min_n,
max_ngram=max_n,
max_model_len=max_model_len,
k=k,
)
valid_ngram_num_drafts[idx] = drafter_output.shape[0]
if len(drafter_output):
valid_ngram_draft[idx, : drafter_output.shape[0]] = drafter_output
def _find_longest_matched_ngram_and_propose_tokens(origin_tokens, min_ngram, max_ngram, max_model_len, k):
# use Knuth–Morris–Pratt (KMP) algorithm to match longest pattern
# this video explains it **neatly**: https://www.youtube.com/watch?v=JoF0Z7nVSrA
# if you're not familiar with it, it's worth a watch
EAGLE
Although the small draft model looks good in theory, in practice it is still lacking because these are fundamentally two different models that learn different things.
An interesting technique is EAGLE, which has several iterations: EAGLE1, EAGLE2, EAGLE3, and most recently EAGLE3.1. The key idea is that the target model is already doing most of the heavy lifting and has all the information needed to predict the next tokens. Some of that information lives in the intermediate hidden states.
So instead of relying only on the token embedding, EAGLE uses the embedding plus hidden states from the target model as input to a lightweight draft network. That draft network then predicts the next token.
In vLLM’s EAGLE-3 setup, the target model produces hidden states at selected layers. Those states are concatenated and projected through a fully connected layer, then passed through lightweight decoder layers and an LM head to produce draft logits. The draft model is still autoregressive, but it relies on the target model’s hidden states.
Essentially, we add a new decode layer that takes as input all the tokens including the last sampled one and their hidden layers, then uses that information to predict the next draft token.
For the first draft token, we do not have a target-model hidden state for the new token yet, so the draft model has to rely on the hidden states it already has. That is one reason why the hidden state design matters.
The main difference between earlier EAGLE versions and EAGLE3 is that the earlier versions focused on the last hidden layer, while EAGLE3 uses multiple layers, usually spanning early, middle, and late stages, to capture a broader view of the model’s reasoning.
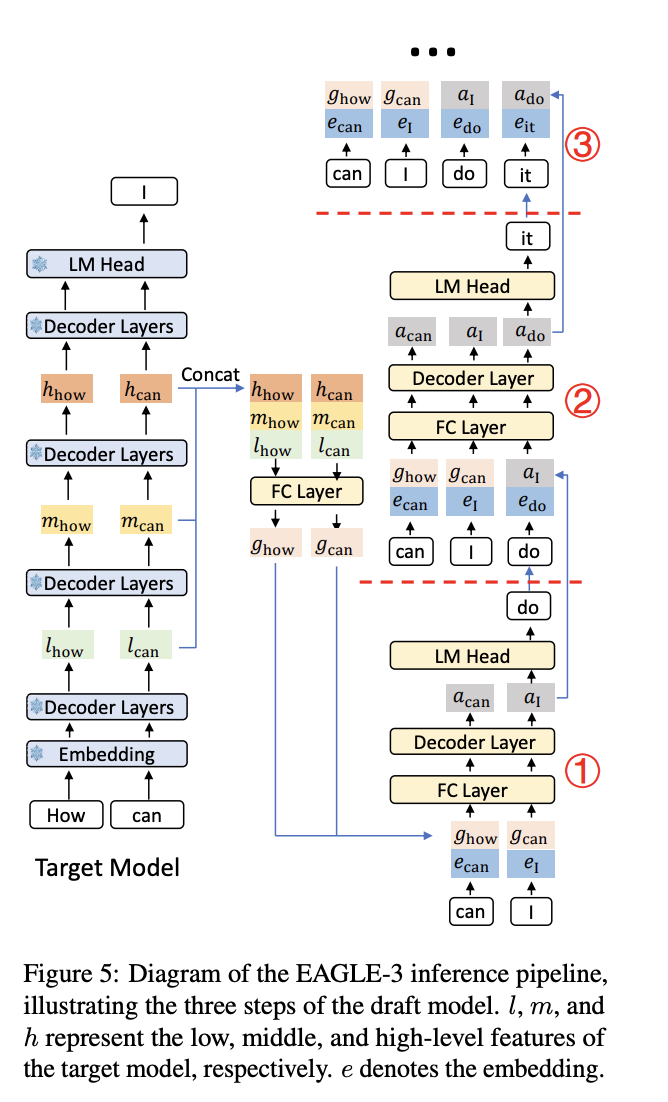
The diagram above from the EAGLE3 paper illustrates the idea. We had “How can” and we just predicted “I” using the target model. For each predicted token i, the hidden state that led to it comes from i-1. So “How”’s hidden state led to “can”, and “can”’s hidden state led to “I”. In the draft model, we combine the hidden state of i-1 with the token embedding of i.
The hidden states from low, middle, and high layers are used. For each token, those hidden state vectors are concatenated and combined using a learned fully connected block that is trained to pick and combine the relevant information across the different stages.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
# vllm/v1/worker/gpu/spec_decode/eagle/speculator.py:405-567
@torch.inference_mode()
def propose(
self,
input_batch: InputBatch,
attn_metadata: dict[str, Any],
slot_mappings: dict[str, torch.Tensor],
last_hidden_states: torch.Tensor, # [num_tokens, H] — target's final layer
aux_hidden_states: list[torch.Tensor] | None, # EAGLE-3: 3 × [num_tokens, H]
num_sampled: torch.Tensor, # [num_reqs] — accepted count from prev iter
num_rejected: torch.Tensor, # [num_reqs] — rejected count from prev iter
last_sampled: torch.Tensor, # [max_num_reqs] — last accepted token/request
next_prefill_tokens: torch.Tensor, # [max_num_reqs] — for chunked prefills
temperature: torch.Tensor,
seeds: torch.Tensor,
...
) -> torch.Tensor:
num_tokens = input_batch.num_tokens_after_padding
num_reqs = input_batch.num_reqs
max_query_len = input_batch.num_scheduled_tokens.max()
# STEP 1: FC FUSION (EAGLE-3 only)
if aux_hidden_states:
assert self.method == "eagle3"
hidden_states = self.model.combine_hidden_states(
torch.cat(aux_hidden_states, dim=-1)
)
else:
# EAGLE-1/2: use final hidden states directly (no fusion)
hidden_states = last_hidden_states
# STEP 2: PREPARE EAGLE INPUTS (Triton kernel)
prepare_eagle_inputs(
self.input_buffers, input_batch, self.last_token_indices,
num_sampled, num_rejected, last_sampled, next_prefill_tokens,
self.max_num_reqs,
)
# STEP 3: PREFILL — GENERATE DRAFT TOKEN 0
self.prefill(
num_reqs, prefill_batch_desc.num_tokens,
attn_metadata, slot_mappings,
num_tokens_across_dp=num_tokens_across_dp,
cudagraph_runtime_mode=prefill_batch_desc.cg_mode,
mm_inputs=mm_inputs,
)
# STEP 4: PREPARE DECODE — TRANSITION TO AUTOREGRESSIVE MODE
prepare_eagle_decode(
self.draft_tokens[:num_reqs, 0], input_batch.seq_lens,
num_rejected, self.input_buffers, self.max_model_len, self.max_num_reqs,
)
# STEP 5: DECODE LOOP — GENERATE DRAFT TOKENS 1..K-1
self.generate_draft(
num_reqs, decode_batch_desc.num_tokens,
attn_metadata_updated, slot_mappings_updated,
num_tokens_across_dp=num_tokens_across_dp,
cudagraph_runtime_mode=decode_batch_desc.cg_mode,
)
return self.draft_tokens[:num_reqs] # [num_reqs, K]
## generating draft tokens is still auto-regressive hence the for loop
def generate_draft(self, num_reqs, num_tokens_padded, attn_metadata, slot_mappings, ...):
pos = self.input_buffers.positions[:num_reqs]
query_start_loc = self.input_buffers.query_start_loc[:num_reqs + 1]
idx_mapping = self.idx_mapping[:num_reqs]
# ── ITERATE THROUGH DRAFT POSITIONS 1, 2, ..., K-1 ──
for step in range(1, self.num_speculative_steps):
# EAGLE forward: 1 token per request (decode mode)
# Uses hidden_states from previous step + embed(prev_draft_token) as input
last_hidden_states, hidden_states = self.run_model(
num_tokens_padded, attn_metadata, slot_mappings, ...
)
last_hidden_states = last_hidden_states[:num_reqs]
hidden_states = hidden_states[:num_reqs]
# We have the final output of the EAGLE model
# We compute logits then sample the draft tokens
logits = self.model.compute_logits(last_hidden_states)
draft_tokens = self._sample_draft(logits, idx_mapping, pos, step=step)
self.draft_tokens[:num_reqs, step] = draft_tokens
# ── UPDATE STATE FOR NEXT STEP (unless this is the final step) ──
if step < self.num_speculative_steps - 1:
# ...
update_eagle_inputs(
draft_tokens, hidden_states,
self.input_buffers, self.hidden_states, self.max_model_len,
)
# ...
There is one subtlety worth calling out because it is quite interesting. When generating draft tokens beyond the first one (tokens 2 through k), we use hidden states from the draft model itself. In the diagram above (steps 2 and 3 on the right), this corresponds to using a_i and a_do from the draft model rather than g_i and g_do from the target model, which contain the true hidden states.
When a draft token is verified and accepted, the corresponding true hidden states from the target model are then passed back to the draft model. At that point, the draft “prefill” step (step 3 in the propose method) recomputes and repopulates the draft KV cache using this corrected information because the “prefill” uses the same slot/attention metadata as the target’s.
EAGLE models are trained separately and are their own models. We can find EAGLE3 models for a variety of open models, for example here. vLLM also has a project to train draft models, such as EAGLE, called speculators, which integrates seamlessly with vLLM.
MTP
EAGLE is a draft model that adds an extra decode path so we can efficiently predict extra draft tokens.
Could we merge a similar extra layer into the target model itself and make it part of the model? That is what MTP is. Some models, such as DeepSeek-family models, include an extra multi-token prediction layer near the end of the network. When a new token is sampled, its embedding plus the hidden state of the last layer are passed to the MTP layer to predict the token that comes right after it. The same LM head and embedding are reused.
This is very similar to EAGLE, except that the model was trained with MTP from the start, it’s even part of the loss function. We can have more than one MTP layer to generate more draft tokens, or we can reuse the MTP layer to predict extra draft tokens, although accuracy will probably drop.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Given context: "The quick brown fox jumps over the"
Target model forward pass:
h = model("The quick brown fox jumps over the")
token_1 = sample(lm_head(h)) = "lazy"
Store: h (hidden state at position "the")
# we predicted "lazy" using the hidden state at position "the"
# we use both in MTP layer 0
MTP Layer 0:
Input: embed("lazy") ⊕ h
Output: h_mtp0
token_2 = argmax(lm_head(h_mtp0)) = "dog"
# Same logic as above
MTP Layer 1 (or Layer 0 reused):
Input: embed("dog") ⊕ h_mtp0
Output: h_mtp1
token_3 = argmax(lm_head(h_mtp1)) = "and"
Draft: ["lazy", "dog", "and"]
If we venture to HuggingFace and look at DeepSeek-v4 weights, we can observe the single MTP.0 layer sitting all by itself after the other 61 regular layers:
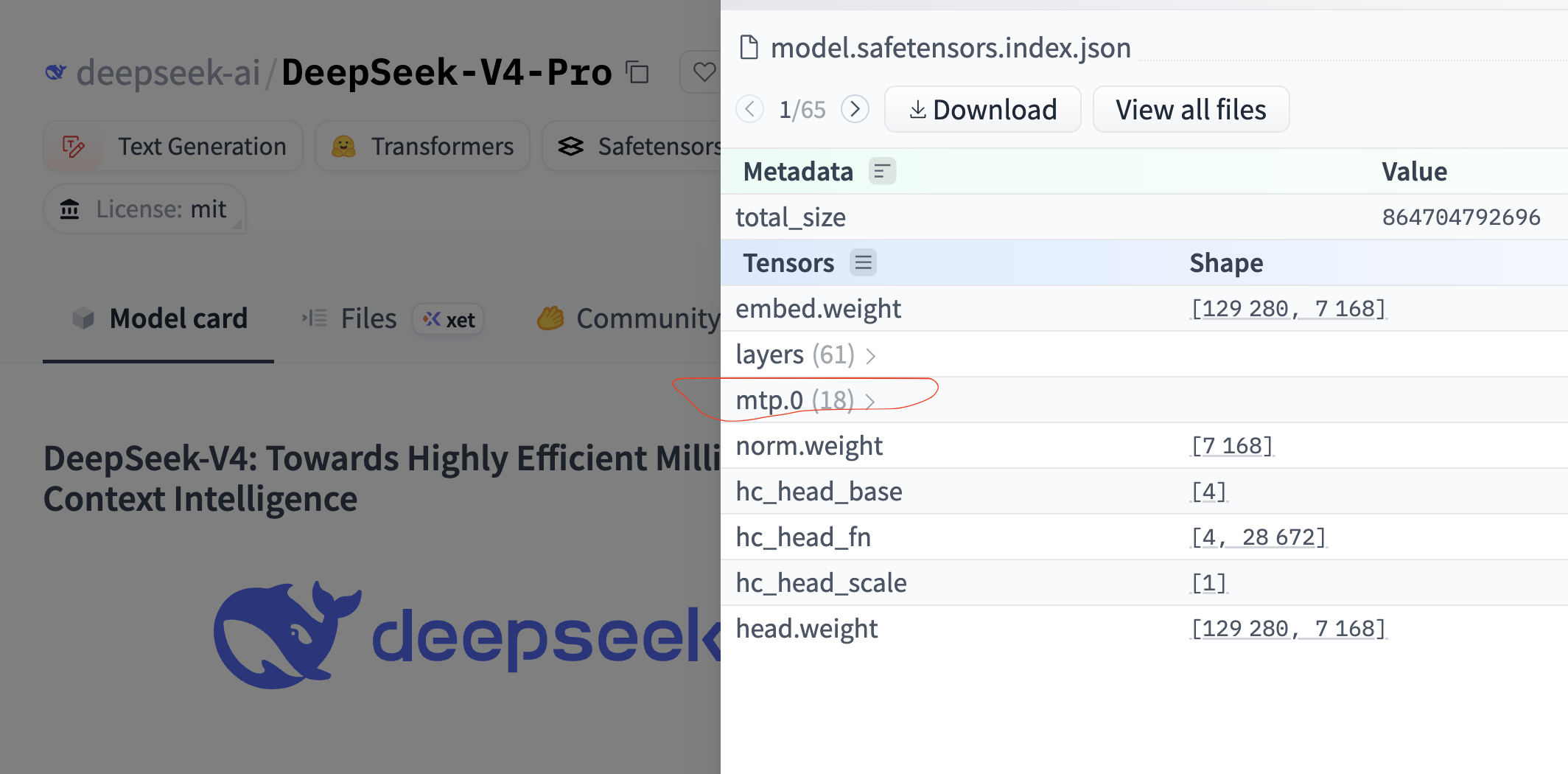
Let’s look at the code. There’s nothing out of the ordinary. Take the input emebeddings and the hidden states that led to them, normalize so we can bring them to similar magnitudes then we concatenate and project them so they can be fed into a regular decode layer.
The generated draft token is then verified by being run through all the model layers.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
class DeepSeekMultiTokenPredictorLayer(nn.Module):
def __init__(self, vllm_config, prefix):
# MTP reuses the model's own embedding + hidden-state path.
config = vllm_config.speculative_config.draft_model_config.hf_config
self.enorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.hnorm = RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.eh_proj = nn.Linear(config.hidden_size * 2, config.hidden_size, bias=False)
self.shared_head = SharedHead(config=config, prefix=prefix, quant_config=...)
self.mtp_block = DeepseekV2DecoderLayer(vllm_config, prefix, config=config, topk_indices_buffer=...)
def forward(self, input_ids, positions, previous_hidden_states, inputs_embeds=None, spec_step_index=0):
assert inputs_embeds is not None
# Position 0 is masked out because MTP only needs the shifted context.
inputs_embeds = torch.where(positions.unsqueeze(-1) == 0, 0, inputs_embeds)
inputs_embeds = self.enorm(inputs_embeds)
previous_hidden_states = self.hnorm(previous_hidden_states)
# Fuse the current embedding with the previous hidden state.
hidden_states = self.eh_proj(torch.cat([inputs_embeds, previous_hidden_states], dim=-1))
# One extra decoder block turns that fused state into draft logits.
hidden_states, residual = self.mtp_block(positions=positions, hidden_states=hidden_states, residual=None)
return residual + hidden_states
class DeepSeekMultiTokenPredictor(nn.Module):
def __init__(self, vllm_config, prefix=""):
config = vllm_config.model_config.hf_config
self.mtp_start_layer_idx = config.num_hidden_layers
self.num_mtp_layers = config.num_nextn_predict_layers
self.layers = nn.ModuleDict({...})
self.embed_tokens = VocabParallelEmbedding(...)
self.logits_processor = LogitsProcessor(config.vocab_size)
def forward(self, input_ids, positions, previous_hidden_states, inputs_embeds=None, spec_step_idx=0):
current_step_idx = spec_step_idx % self.num_mtp_layers # cycle throught the layer if num of draft tokens is larger than num of mtp layers
return self.layers[str(self.mtp_start_layer_idx + current_step_idx)](
input_ids, positions, previous_hidden_states, inputs_embeds, current_step_idx
)
def compute_logits(self, hidden_states, spec_step_idx=0):
mtp_layer = self.layers[str(self.mtp_start_layer_idx + (spec_step_idx % self.num_mtp_layers))]
# notice the "shared_head"
return self.logits_processor(mtp_layer.shared_head.head, mtp_layer.shared_head(hidden_states))