Exploring Kafka Streams Internals
A Look Under the Hood of Kafka Streams
Intro
In a couple of my recent posts, I explored the Kafka broker and the Kafka producer internals — quite a bit of fun.
In this post, I’m taking a stab at Kafka Streams. This part of Kafka has always held a certain mystique for me, and this is my attempt to dive head-on into that aura of mystery.
As always, the goal is to peek at various interesting bits and pieces of the code to see how they fit together. This is purely for fun and serves as a collection of notes I took while exploring the code.
If you spot any mistakes or have suggestions, please feel free to get in touch!
Why Do We Need Kafka Streams?
If you are familiar with Kafka Streams, feel free to skip this section.
The question strikes me as both insightful and a bit naive at the same time. Kafka exists because people need to move considerable amounts of data from point A to point B. Oftentimes, this data needs multiple transformations—read message(s), enrich, transform, compute, and then write. Then do it all over again.
It turns out this pattern is quite common. And quite repetitive.
What do we do in software when faced with repetition? We create libraries, tools, and abstractions to help tame the mundane. That’s what Kafka Streams is.
It brings some structure and predictability to the chaos of stream processing.
Here is a diagram taken from the official doc, which is really a good read: 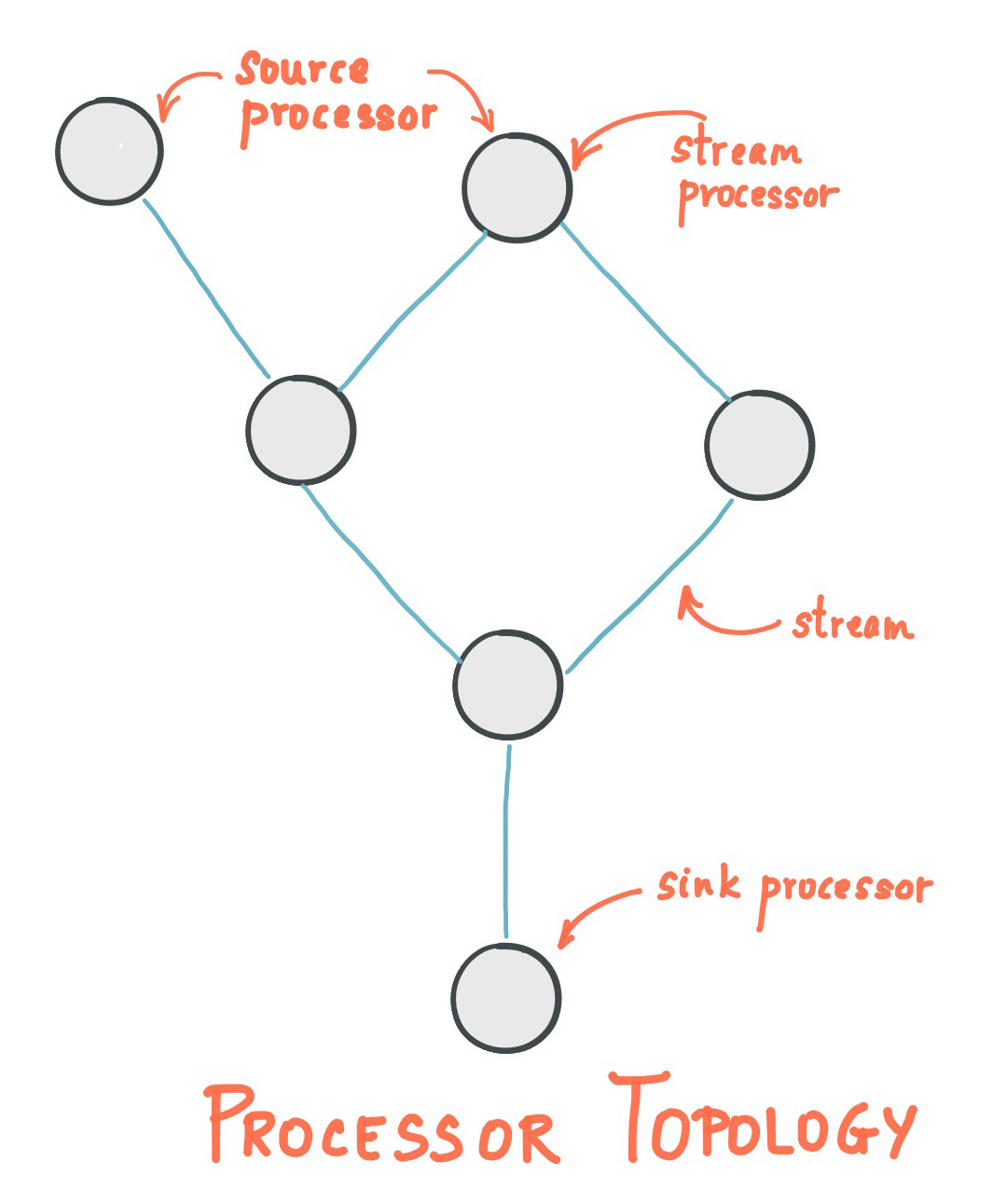
It also brings useful concepts and abstraction. KStream, KTable, Aggregatioms, Windowing, State Stores, etc.
The “Hello-World” example from the Kafka docs is as follows::
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
Topology topology = ...;
// Use the configuration to tell your application where the Kafka cluster is,
// which Serializers/Deserializers to use by default, to specify security settings,
// and so on.
Properties props = ...;
KafkaStreams streams = new KafkaStreams(topology, props);
// Construct a `KStream` from the input topic "streams-plaintext-input", where message values
// represent lines of text (for the sake of this example, we ignore whatever may be stored
// in the message keys).
KStream<String, String> textLines = builder.stream(
"streams-plaintext-input",
Consumed.with(stringSerde, stringSerde)
);
KTable<String, Long> wordCounts = textLines
// Split each text line, by whitespace, into words.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// Group the text words as message keys
.groupBy((key, value) -> value)
// Count the occurrences of each word (message key).
.count();
// Store the running counts as a changelog stream to the output topic.
wordCounts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
// Start the Kafka Streams threads
streams.start();
streams-plaintext-input is a topic where message values are lines of text. We consume those lines, split them into words, and count the occurrences.
The main value-add? Why use Kafka Streams for this?
First of all, this is an infinite stream. It could run for weeks, months, or even years. What happens if we have hundreds of terabytes of data? We’ll need multiple instances. Each instance must handle a portion of the data.
Here’s where the beauty of Kafka Streams comes in: provided the topic has N partitions, we can have up to N instances running this exact same code, inside any Java program (it’s just a library), and it will scale. It will work seamlessly and be fault-tolerant.
The state (word count per partition) is persisted to a changelog topic (a simple compact topic). If one instance fails, another one simply picks up its partitions using the underlying Kafka consumer group protocol.
And this isn’t limited to simple word counts, the same mechanisms apply to time-based aggregations or to any custom logic, stateful or stateless, as complex or as simple as needed.
That’s the real power:
Imagine a message arriving at a source topic, then traversing a dozen-plus processor nodes—applying business rules, enrichment, filtering, and calculations based on existing state—before being written to an output topic. All of this, with built-in resilience, fault-tolerance, and real-time guarantees.
Topology
A Kafka Streams topology is a Directed Acyclic Graph (DAG) of nodes.
- Source nodes read data from Kafka topics.
- Processor nodes receive data from one or more source or other processor nodes, perform processing and transformations (which can be stateful), and forward the results to other nodes, either more processors or sinks.
- Sink nodes push the final results to Kafka topics.
If a processor node writes data to a topic, and another part of the graph reads from that topic, the topology is split into sub-topologies. These sub-topologies are not directly connected but are logically linked through the intermediate Kafka topic.
DSL vs Processor API
Kafka Streams requires a topology that defines how data flows from source topics to sinks, and how it is processed and transformed along the way through processor nodes.
The library offers two main ways to define this topology:
Processor API: This is the low-level API for defining custom processing logic. A that class that implements a
processmethod that’s called for each incoming record. The processor has access to the processing context (topic, partition, timestamp) and, if needed, a state store which is really a key/value store interface.1 2 3 4 5 6 7 8 9 10 11 12 13 14
public interface KeyValueStore<K, V> extends StateStore, ReadOnlyKeyValueStore<K, V> { void put(K key, V value); V putIfAbsent(K key, V value); void putAll(List<KeyValue<K, V>> entries); V delete(K key); } public interface ReadOnlyKeyValueStore<K, V> { // ... V get(K key); // ... }
Two handy implementations of notes: InMemory store which is really a wrapper around a Java
TreeMapand a RocksDB store which wraps the RocksDB database.Processors can also perform scheduled operations, known as punctuation. This is useful for emitting results of ongoing computations or triggering time-based logic.
DSL (Domain-Specific Language): Most streaming applications need common operations like join, aggregate, filter, etc. Kafka Streams provides high-level abstractions to express these operations in a concise and declarative way. It introduces
KStreamandKTableto describe data flows and transformations.The DSL is a layer on top of of the Processor API and it compiles down to the same kind of topology under the hood. The next logical evolution of the DSL is ksqlDB, a SQL-like streaming query language built on top of Kafka Streams.
In the end, these two approaches are simply different ways to describe the same thing: a topology. Whether we use the Processor API, the DSL, or ksqlDB, the resulting topology consists of nodes with logic defined in their process methods, connected by a flow of records, with access to state stores for stateful operations and mechanisms to forward data downstream.
Official Doc: Kafka Streams Architecture 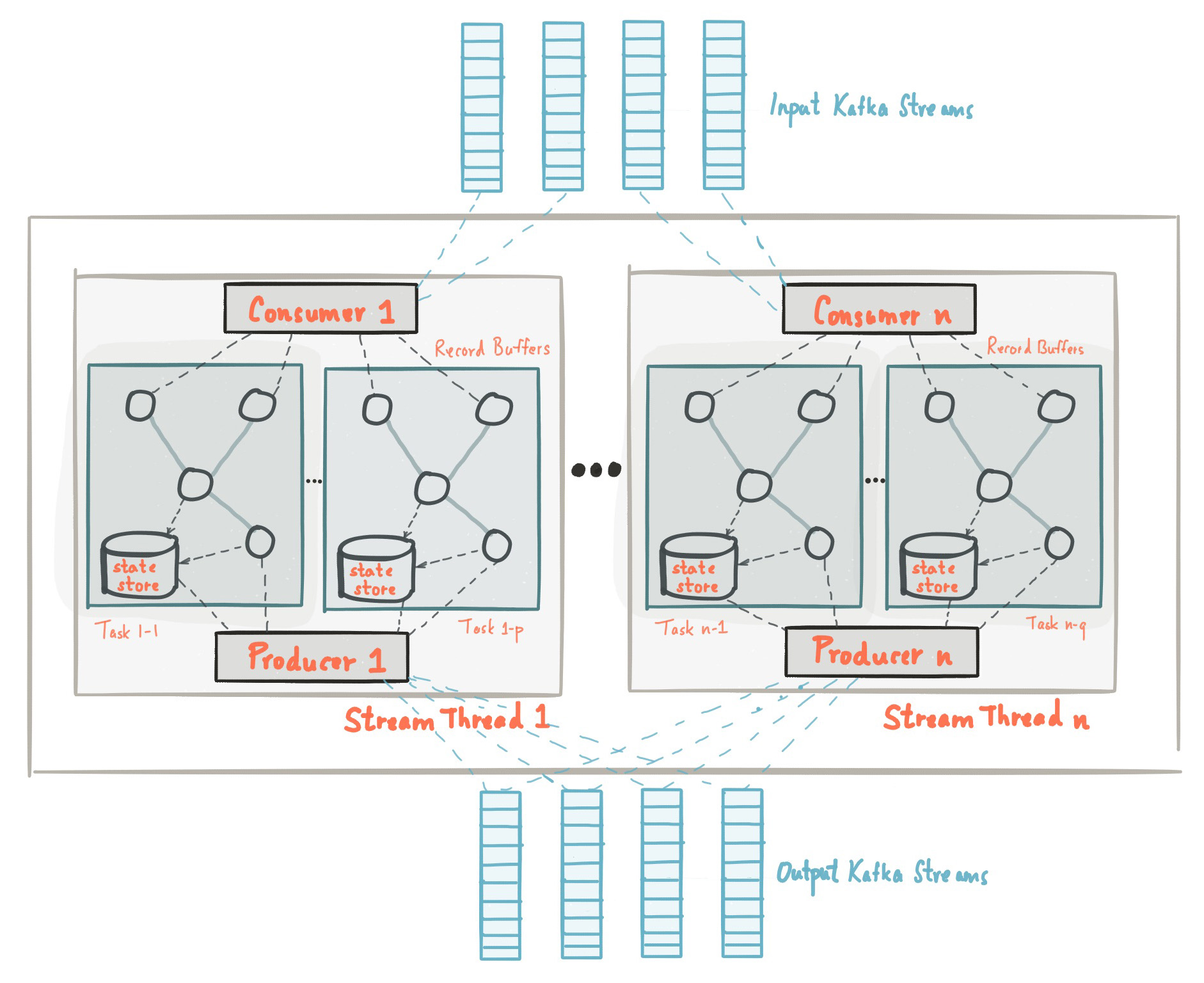
Let’s now take a closer look at those nodes.
Processor Nodes
All nodes extend the Processor node.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
public class ProcessorNode<KIn, VIn, KOut, VOut> {
private final List<ProcessorNode<KOut, VOut, ?, ?>> children;
private final Map<String, ProcessorNode<KOut, VOut, ?, ?>> childByName;
private final Processor<KIn, VIn, KOut, VOut> processor;
private final String name;
public final Set<String> stateStores;
private InternalProcessorContext<KOut, VOut> internalProcessorContext;
public void process(final Record<KIn, VIn> record) {
//...
if (processor != null) {
processor.process(record);
}
//...
}
}
public interface Processor<KIn, VIn, KOut, VOut> {
/**
* Initialize this processor with the given context. The framework ensures this is called once per processor when the topology
* that contains it is initialized. When the framework is done with the processor, {@link #close()} will be called on it; the
* framework may later re-use the processor by calling {@code #init()} again.
* <p>
* The provided {@link ProcessorContext context} can be used to access topology and record meta data, to
* {@link ProcessorContext#schedule(Duration, PunctuationType, Punctuator) schedule} a method to be
* {@link Punctuator#punctuate(long) called periodically} and to access attached {@link StateStore}s.
*
* @param context the context; may not be null
*/
default void init(final ProcessorContext<KOut, VOut> context) {}
/**
* Process the record. Note that record metadata is undefined in cases such as a forward call from a punctuator.
*
* @param record the record to process
*/
void process(Record<KIn, VIn> record);
default void close() {}
}
A ProcessorNode has:
- Children: downstream nodes to which it can forward records
- State stores: for maintaining local state during processing
- A
ProcessingContext: which provides metadata (topic, partition, offset, timestamp) and essential APIs
At its core, a ProcessorNode holds a Processor object. The key method in that object is process, which performs the actual record processing.
The ProcessingContext provides the forward method, allowing a processor to pass a record to specific child nodes or broadcast it to all of them.
Forwarding under the hood is quite simple:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
public <K, V> void forward(final Record<K, V> record, final String childName) {
// ...
if (childName == null) {
final List<? extends ProcessorNode<?, ?, ?, ?>> children = currentNode().children();
for (final ProcessorNode<?, ?, ?, ?> child : children) {
forwardInternal((ProcessorNode<K, V, ?, ?>) child, record);
}
} else {
final ProcessorNode<?, ?, ?, ?> child = currentNode().child(childName);
if (child == null) {
throw new StreamsException("Unknown downstream node: " + childName
+ " either does not exist or is not connected to this processor.");
}
forwardInternal((ProcessorNode<K, V, ?, ?>) child, record);
}
// ...
}
// ...
private <K, V> void forwardInternal(final ProcessorNode<K, V, ?, ?> child,
final Record<K, V> record) {
setCurrentNode(child);
child.process(record);
// ...
}
Get the child node, then call its process method, which might call forward again, passing data to its own children, and so on. This is how records traverse the topology, relying on the magic of recursion.
Source Node
1
2
3
4
5
6
7
8
9
10
11
12
public class SourceNode<KIn, VIn> extends ProcessorNode<KIn, VIn, KIn, VIn> {
private InternalProcessorContext<KIn, VIn> context;
private Deserializer<KIn> keyDeserializer;
private Deserializer<VIn> valDeserializer;
\
@Override
public void process(final Record<KIn, VIn> record) {
context.forward(record);
}
}
The SourceNode is responsible for reading data from a topic and deserializing it. Its process method simply forwards the data to its child processors.
Sink Node
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
public class SinkNode<KIn, VIn> extends ProcessorNode<KIn, VIn, Void, Void> {
private Serializer<KIn> keySerializer;
private Serializer<VIn> valSerializer;
private final TopicNameExtractor<? super KIn, ? super VIn> topicExtractor;
private final StreamPartitioner<? super KIn, ? super VIn> partitioner;
private InternalProcessorContext<Void, Void> context;
@Override
public void process(final Record<KIn, VIn> record) {
final RecordCollector collector = ((RecordCollector.Supplier) context).recordCollector();
final KIn key = record.key();
final VIn value = record.value();
// ...
collector.send(
topic,
key,
value,
record.headers(),
timestamp,
keySerializer,
valSerializer,
name(),
context,
partitioner);
}
SinkNode is responsible for sending data to topics. It thus needs a Serializer for the key and value. Its process method does just that. The RecordCollector is a wrapper around a KafkaProducer. It adds proper exception handling but also makes use of a StreamPartitioner, which determines which partition the record should be sent to, it currently uses the DefaultPartitioner but also a WindowedStreamPartitioner which uses the window information in addition to the message key to pick a partition.
Running and Threading Model
Kafka Streams is not a standalone resource manager: it’s a library that can be added to any Java application and run anywhere.
Multiple instances of the application that share the same application.id will automatically share the workload. These instances can run on different machines, the same machine, Kubernetes pods, etc.
Work is divided into tasks, where each task handles one or more topic-partitions.
Each Kafka Streams instance has a configurable number of stream threads, and each task is executed within one of those threads.
To summarize:
1
topic partitions ≥ tasks ≥ threads ≥ instances
Partitions are distributed across tasks, tasks are assigned to threads, and threads live inside instances.
The more threads and instances you run, the more parallel copies of the Kafka Streams flow you have—each handling a subset of the data (i.e., a subset of partitions).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
/**
* A Kafka client that allows for performing continuous computation on input coming from one or more input topics and
* sends output to zero, one, or more output topics.
* <p>
* The computational logic can be specified either by using the {@link Topology} to define a DAG topology of
* {@link org.apache.kafka.streams.processor.api.Processor}s or by using the {@link StreamsBuilder} which provides the high-level DSL to define
* transformations.
* <p>
* One {@code KafkaStreams} instance can contain one or more threads specified in the configs for the processing work.
* <p>
* A {@code KafkaStreams} instance can co-ordinate with any other instances with the same
* {@link StreamsConfig#APPLICATION_ID_CONFIG application ID} (whether in the same process, on other processes on this
* machine, or on remote machines) as a single (possibly distributed) stream processing application.
* These instances will divide up the work based on the assignment of the input topic partitions so that all partitions
* are being consumed.
* If instances are added or fail, all (remaining) instances will rebalance the partition assignment among themselves
* to balance processing load and ensure that all input topic partitions are processed.
* <p>
* Internally a {@code KafkaStreams} instance contains a normal {@link KafkaProducer} and {@link KafkaConsumer} instance
* that is used for reading input and writing output.
*/
public class KafkaStreams implements AutoCloseable {
private final Time time;
private final Logger log;
protected final String clientId;
private final Metrics metrics;
protected final StreamsConfig applicationConfigs;
protected final List<StreamThread> threads;
protected final StreamsMetadataState streamsMetadataState;
private final ScheduledExecutorService stateDirCleaner;
private final ScheduledExecutorService rocksDBMetricsRecordingService;
protected final Admin adminClient;
private final StreamsMetricsImpl streamsMetrics;
private final long totalCacheSize;
private final StreamStateListener streamStateListener;
private final DelegatingStateRestoreListener delegatingStateRestoreListener;
private final UUID processId;
private final KafkaClientSupplier clientSupplier;
protected final TopologyMetadata topologyMetadata;
private final QueryableStoreProvider queryableStoreProvider;
private final DelegatingStandbyUpdateListener delegatingStandbyUpdateListener;
private final LogContext logContext;
GlobalStreamThread globalStreamThread;
protected StateDirectory stateDirectory = null;
private KafkaStreams.StateListener stateListener;
private BiConsumer<Throwable, Boolean> streamsUncaughtExceptionHandler;
private final Object changeThreadCount = new Object();
// ...
}
The KafkaStreams class has a lot of things going on.
applicationConfigs: Holds configuration settings for the Kafka Streams application.threads: List of StreamThread instances for parallel stream processing.stateDirCleaner: Scheduled executor for cleaning up local state directories.adminClient: Kafka Admin client for cluster metadata operations.totalCacheSize: Total memory allocated for caching state stores.topologyMetadata: Metadata describing the processing topology.clientSupplier: Supplies Kafka clients (e.g., producers, consumers).globalStreamThread: Thread that runs the global state store logic.
A trimmed down constructor looks like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
private KafkaStreams(final TopologyMetadata topologyMetadata,
final StreamsConfig applicationConfigs,
final KafkaClientSupplier clientSupplier,
final Time time) throws StreamsException {
this.applicationConfigs = applicationConfigs;
this.time = time;
this.topologyMetadata = topologyMetadata;
this.topologyMetadata.buildAndRewriteTopology();
final boolean hasGlobalTopology = topologyMetadata.hasGlobalTopology();
try {
stateDirectory = new StateDirectory(applicationConfigs, time, topologyMetadata.hasPersistentStores(), topologyMetadata.hasNamedTopologies());
processId = stateDirectory.initializeProcessId();
} catch (final ProcessorStateException fatal) {
Utils.closeQuietly(stateDirectory, "streams state directory");
throw new StreamsException(fatal);
}
// The application ID is a required config and hence should always have value
final String userClientId = applicationConfigs.getString(StreamsConfig.CLIENT_ID_CONFIG);
final String applicationId = applicationConfigs.getString(StreamsConfig.APPLICATION_ID_CONFIG);
this.clientSupplier = clientSupplier;
log.info("Kafka Streams version: {}", ClientMetrics.version());
log.info("Kafka Streams commit ID: {}", ClientMetrics.commitId());
// use client id instead of thread client id since this admin client may be shared among threads
adminClient = clientSupplier.getAdmin(applicationConfigs.getAdminConfigs(ClientUtils.adminClientId(clientId)));
threads = Collections.synchronizedList(new LinkedList<>());
streamsMetadataState = new StreamsMetadataState(
this.topologyMetadata,
parseHostInfo(applicationConfigs.getString(StreamsConfig.APPLICATION_SERVER_CONFIG)),
logContext
);
streamsUncaughtExceptionHandler = (throwable, skipThreadReplacement) -> handleStreamsUncaughtException(throwable, t -> SHUTDOWN_CLIENT, skipThreadReplacement);
totalCacheSize = totalCacheSize(applicationConfigs);
final int numStreamThreads = topologyMetadata.numStreamThreads(applicationConfigs);
final long cacheSizePerThread = cacheSizePerThread(numStreamThreads);
GlobalStreamThread.State globalThreadState = null;
if (hasGlobalTopology) {
final String globalThreadId = clientId + "-GlobalStreamThread";
globalStreamThread = new GlobalStreamThread(
topologyMetadata.globalTaskTopology(),
applicationConfigs,
clientSupplier.getGlobalConsumer(applicationConfigs.getGlobalConsumerConfigs(clientId)),
stateDirectory,
cacheSizePerThread,
streamsMetrics,
time,
globalThreadId,
delegatingStateRestoreListener,
exception -> handleStreamsUncaughtException(exception, t -> SHUTDOWN_CLIENT, false)
);
globalThreadState = globalStreamThread.state();
}
for (int i = 1; i <= numStreamThreads; i++) {
createAndAddStreamThread(cacheSizePerThread, i);
}
stateDirCleaner = setupStateDirCleaner();
rocksDBMetricsRecordingService = maybeCreateRocksDBMetricsRecordingService(clientId, applicationConfigs);
}
We’re extracting values from the properties and initializing various class fields. Notably, this includes the StreamThreads, GlobalStreamThread, and all the components related to state management.
THe streaming party starts with:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
/**
* Start the {@code KafkaStreams} instance by starting all its threads.
* This function is expected to be called only once during the life cycle of the client.
* <p>
* Because threads are started in the background, this method does not block.
* However, if you have global stores in your topology, this method blocks until all global stores are restored.
* As a consequence, any fatal exception that happens during processing is by default only logged.
* If you want to be notified about dying threads, you can
* {@link #setUncaughtExceptionHandler(StreamsUncaughtExceptionHandler) register an uncaught exception handler}
*/
public synchronized void start() throws IllegalStateException, StreamsException {
stateDirectory.initializeStartupTasks(topologyMetadata, streamsMetrics, logContext);
log.debug("Starting Streams client");
if (globalStreamThread != null) {
globalStreamThread.start();
}
final int numThreads = processStreamThread(StreamThread::start);
log.info("Started {} stream threads", numThreads);
final Long cleanupDelay = applicationConfigs.getLong(StreamsConfig.STATE_CLEANUP_DELAY_MS_CONFIG);
stateDirCleaner.scheduleAtFixedRate(() -> {
// we do not use lock here since we only read on the value and act on it
if (state == State.RUNNING) {
stateDirectory.cleanRemovedTasks(cleanupDelay);
}
}, cleanupDelay, cleanupDelay, TimeUnit.MILLISECONDS);
}
So the heavy lifting in KafkaStream instance is really done through the StreamThreads and GlobalStreamThread.
StreamThread
Let’s take a look at StreamThread.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
public static StreamThread create(final TopologyMetadata topologyMetadata,
final StreamsConfig config,
final KafkaClientSupplier clientSupplier,
final Admin adminClient,
final UUID processId,
final String clientId,
final StreamsMetricsImpl streamsMetrics,
final Time time,
final StreamsMetadataState streamsMetadataState,
final long cacheSizeBytes,
final StateDirectory stateDirectory,
final StateRestoreListener userStateRestoreListener,
final StandbyUpdateListener userStandbyUpdateListener,
final int threadIdx,
final Runnable shutdownErrorHook,
final BiConsumer<Throwable, Boolean> streamsUncaughtExceptionHandler) {
final String threadId = clientId + THREAD_ID_SUBSTRING + threadIdx;
final String stateUpdaterId = threadId.replace(THREAD_ID_SUBSTRING, STATE_UPDATER_ID_SUBSTRING);
final String logPrefix = String.format("stream-thread [%s] ", threadId);
final LogContext logContext = new LogContext(logPrefix);
final LogContext restorationLogContext = stateUpdaterEnabled ? new LogContext(String.format("state-updater [%s] ", restorationThreadId)) : logContext;
final Logger log = logContext.logger(StreamThread.class);
final ReferenceContainer referenceContainer = new ReferenceContainer();
referenceContainer.adminClient = adminClient;
referenceContainer.streamsMetadataState = streamsMetadataState;
referenceContainer.time = time;
referenceContainer.clientTags = config.getClientTags();
log.info("Creating restore consumer client");
final Map<String, Object> restoreConsumerConfigs = config.getRestoreConsumerConfigs(restoreConsumerClientId(restorationThreadId));
final Consumer<byte[], byte[]> restoreConsumer = clientSupplier.getRestoreConsumer(restoreConsumerConfigs);
final StoreChangelogReader changelogReader = new StoreChangelogReader(
time,
config,
restorationLogContext,
adminClient,
restoreConsumer,
userStateRestoreListener,
userStandbyUpdateListener
);
final ThreadCache cache = new ThreadCache(logContext, cacheSizeBytes, streamsMetrics);
// ...
final TaskManager taskManager = new TaskManager(
time,
changelogReader,
new ProcessId(processId),
logPrefix,
activeTaskCreator,
standbyTaskCreator,
tasks,
topologyMetadata,
adminClient,
stateDirectory,
stateUpdater,
schedulingTaskManager
);
referenceContainer.taskManager = taskManager;
log.info("Creating consumer client");
final String applicationId = config.getString(StreamsConfig.APPLICATION_ID_CONFIG);
final Map<String, Object> consumerConfigs = config.getMainConsumerConfigs(applicationId, consumerClientId(threadId), threadIdx);
consumerConfigs.put(StreamsConfig.InternalConfig.REFERENCE_CONTAINER_PARTITION_ASSIGNOR, referenceContainer);
final String originalReset = (String) consumerConfigs.get(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG);
// If there are any overrides, we never fall through to the consumer, but only handle offset management ourselves.
if (topologyMetadata.hasOffsetResetOverrides()) {
consumerConfigs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "none");
}
final MainConsumerSetup mainConsumerSetup = setupMainConsumer(topologyMetadata, config, clientSupplier, processId, log, consumerConfigs);
taskManager.setMainConsumer(mainConsumerSetup.mainConsumer);
referenceContainer.mainConsumer = mainConsumerSetup.mainConsumer;
final StreamThread streamThread = new StreamThread(
time,
config,
adminClient,
mainConsumerSetup.mainConsumer,
restoreConsumer,
changelogReader,
originalReset,
taskManager,
stateUpdater,
streamsMetrics,
topologyMetadata,
processId,
threadId,
logContext,
referenceContainer.assignmentErrorCode,
referenceContainer.nextScheduledRebalanceMs,
referenceContainer.nonFatalExceptionsToHandle,
shutdownErrorHook,
streamsUncaughtExceptionHandler,
cache::resize,
mainConsumerSetup.streamsRebalanceData,
streamsMetadataState
);
return streamThread.updateThreadMetadata(adminClientId(clientId));
}
StreamThread has an ActiveTaskCreator, manages its Tasks, and coordinates via a TaskManager.
The consumer group used by the Streams application employs a special assignor that calls the handleAssignment method on the TaskManager, indicating which tasks are assigned to that thread.
I believe that the assignment of partitions to tasks, threads, and application instances is quite fascinating.
Kafka Streams relies on the Kafka Consumer Group protocol.
Recap on Consumer Groups: For regular consumers, a group of consumers share a group.id. The first consumer contacting the brokers becomes the group leader. Other consumers join the group by sending a Join request with their current partition assignments (if any). The leader computes new partition assignments and sends them to the broker, which dispatches them to all consumers. This reassignment happens whenever the number of topic partitions or group members changes.
Kafka Streams builds on this mechanism with its own assignor: StreamsPartitionAssignor (implementing ConsumerPartitionAssignor). Each StreamThread holds a mainConsumer instance subscribed to the topology’s source topics. This subscription happens at the start of the run method in the thread.
In most cases, it runs the following snippet:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// StreamThread
private void subscribeConsumer() {
//...
((ConsumerWrapper) mainConsumer).subscribe(
topologyMetadata.allFullSourceTopicNames(),
new DefaultStreamsRebalanceListener(
log,
time,
streamsRebalanceData.get(),
this,
taskManager
)
);
}
Each StreamThread has its own consumer, and the StreamsPartitionAssignor—via the Consumer Group Protocol (implementing the ConsumerPartitionAssignor interface)—decides how tasks are assigned.
The Consumer Group Protocol supports subscriptionUserData, allowing custom data to be exchanged during group coordination.
A key method in the ConsumerPartitionAssignor interface is assign, which the group leader invokes to compute the partition assignment.
Inside StreamsPartitionAssignor, a call is made to the partitionGroups function, which I believe is a key part of the assignment:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
final Map<TaskId, Set<TopicPartition>> sourcePartitionGroups = new HashMap<>();
for (final Map.Entry<Subtopology, Set<String>> entry : sourceTopicGroups.entrySet()) {
final Subtopology subtopology = entry.getKey();
final Set<String> sourceTopicGroup = entry.getValue();
final int maxNumPartitions = maxNumPartitions(metadata, sourceTopicGroup);
for (int partitionId = 0; partitionId < maxNumPartitions; partitionId++) {
final Set<TopicPartition> sourcePartitionGroup = new HashSet<>(sourceTopicGroup.size());
for (final String topic : sourceTopicGroup) {
final List<PartitionInfo> partitions = metadata.partitionsForTopic(topic);
if (partitionId < partitions.size()) {
sourcePartitionGroup.add(new TopicPartition(topic, partitionId));
}
}
final TaskId taskId = new TaskId(subtopology.nodeGroupId, partitionId, subtopology.namedTopology);
sourcePartitionGroups.put(taskId, Collections.unmodifiableSet(sourcePartitionGroup));
}
}
For each subtopology (a disconnected subgraph within the topology), we determine the maximum number of partitions across all its source topics—this defines the number of tasks. Each task is identified by a TaskId, which is a tuple consisting of the Subtopology ID, partition, and topology name.
Once we have the tasks (with their associated partitions), these tasks need to be assigned to threads across instances.
StreamThread consumers send custom subscription user data during the consumer group Join request. The leader then computes the new assignment based on the global state.
The assign method first computes the assignment at the process (instance) level, then further distributes tasks among the threads within that process.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
// compute the assignment of tasks to threads within each client and build the final group assignment
final Map<String, Assignment> assignment = computeNewAssignment(
statefulTasks,
clientMetadataMap,
partitionsForTask,
partitionsByHost,
standbyPartitionsByHost,
allOwnedPartitions,
minReceivedMetadataVersion,
minSupportedMetadataVersion,
versionProbing
);
// And further inside
final AssignmentInfo info = new AssignmentInfo(
minUserMetadataVersion,
minSupportedMetadataVersion,
assignedActiveList,
standbyTaskMap,
partitionsByHostState,
standbyPartitionsByHost,
AssignorError.NONE.code()
);
assignment.put(
consumer,
new Assignment(
activePartitionsList,
info.encode()
)
);
The StreamThread consumers receive their assigned partitions (activePartitionsList), as well as the list of active and standby tasks by host (instance).
An important detail: the StreamsPartitionAssignor doesn’t have direct access to the StreamThread, and vice versa. However, they need to share information. To bridge this gap, the StreamThread sets a referenceContainer in the consumer configurations:
1
consumerConfigs.put(StreamsConfig.InternalConfig.REFERENCE_CONTAINER_PARTITION_ASSIGNOR, referenceContainer);
Since the assignor has access to the consumer configs, it can retrieve this reference container, which holds useful shared references such as the TaskManager.
After the assignment is determined, each StreamThread calls its TaskManager’s handleAssignment method to create and update the assigned tasks. Let’s remember, StreamThread represents a consumer with multiple task, the partition assignment is at the consumer level, then each consumer has N tasks (where N is max number of source topic partitions). The task is a nice abstraction to divide work within a consumer/thread.
For active tasks, the task implementation class is StreamTask.
So, how does the actual stream processing take place?
The KafkaStreams class starts StreamThreads. A StreamThread’s run() method looks roughly like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
/**
* Main event loop for polling, and processing records through topologies.
*
* @throws IllegalStateException If store gets registered after initialized is already finished
* @throws StreamsException if the store's change log does not contain the partition
*/
boolean runLoop() {
subscribeConsumer();
// if the thread is still in the middle of a rebalance, we should keep polling
// until the rebalance is completed before we close and commit the tasks
while (isRunning() || taskManager.rebalanceInProgress()) {
try {
checkForTopologyUpdates();
//...
runOnceWithoutProcessingThreads()
//..
}
return true;
}
}
subscribeConsumer is how the thread’s consumer subscribes to the topology’s source topics and gets data for its tasks. The real processing happens within the following infinite, breakable loop:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
/**
* One iteration of a thread includes the following steps:
* <p>
* 1. poll records from main consumer and add to buffer;
* 2. restore from restore consumer and update standby tasks if necessary;
* 3. process active tasks from the buffers;
* 4. punctuate active tasks if necessary;
* 5. commit all tasks if necessary;
*
* <p> Among them, step 3/4/5 is done in batches in which we try to process as much as possible while trying to
* stop iteration to call the next iteration when it's close to the next main consumer's poll deadline
*
* @throws IllegalStateException If store gets registered after initialized is already finished
* @throws StreamsException If the store's change log does not contain the partition
* @throws TaskMigratedException If another thread wrote to the changelog topic that is currently restored
* or if committing offsets failed (non-EOS)
* or if the task producer got fenced (EOS)
*/
// Visible for testing
void runOnceWithoutProcessingThreads() {
// ...
// polls records and add to task-specific queues
pollLatency = pollPhase();
/*
* Within an iteration, after processing up to N (N initialized as 1 upon start up) records for each applicable tasks, check the current time:
* 1. If it is time to punctuate, do it;
* 2. If it is time to commit, do it, this should be after 1) since punctuate may trigger commit;
* 3. If there's no records processed, end the current iteration immediately;
* 4. If we are close to consumer's next poll deadline, end the current iteration immediately;
* 5. If any of 1), 2) and 4) happens, half N for next iteration;
* 6. Otherwise, increment N.
*/
do {
if (stateUpdaterEnabled) {
checkStateUpdater();
}
log.debug("Processing tasks with {} iterations.", numIterations);
final int processed = taskManager.process(numIterations, time); // <===== T
// ...
log.debug("Processed {} records with {} iterations; invoking punctuators if necessary",
processed,
numIterations);
final int punctuated = taskManager.punctuate();
// ...
log.debug("{} punctuators ran.", punctuated);
final int committed = maybeCommit();
// ...
} while (true);
}
taskManager.process(numIterations, time) is the crucial line. The TaskManager iterates over all tasks assigned to the StreamThread—each corresponding to one or more topic partitions—fetches records from their queues (populated from the source topic partitions), and calls process on the first SourceNode.
This process call cascades through the process methods of all nodes in the topology. Each node applies its transformations, updating any relevant state stores along the way, until the flow reaches a SinkNode. The SinkNode’s process method simply produces the resulting data to the configured sink topics.
TODO
- GlobalThread, global state stores
- Inspecting how DSL abstractions are implemented: Kstream, Ktable. Aggregation, etc.
- Deep dive into state stores and RocksDB in particular.
Conclusion
Saying we barely scratched the surface is an understatement. But looking into the innermost parts of the implementation and seeing how the different pieces come together to make this magnificent library work brings me a great deal of satisfaction.
Get in touch on Twitter/X at @moncef_abboud.